Building a Full-Stack AI-Powered Feature on Bing
When you search the web you usually see a bunch of links in the results, you click on one of them, and quickly forget about that search engine.
But behind those blue links and media content, there is some deep science, engineering and mathematics that take place.
In this post I'll explain the high-level process (well, there will be some details) to build a very small feature, but you'll see how much effort and science go into it.
Not rocket science, but gets very close to it.
At Bing (in particular the Visual System and SERP Experiences group) we've recently shipped a cool feature for mobile devices: say that you're searching on Google for a specific app: "1 second everyday app" (the current number #1 free app in the app store). This is what you get:
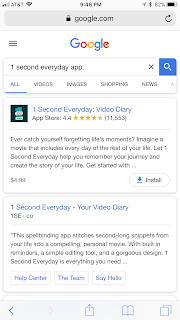
As you can see the very first result is what you're looking for. Job well done.
When you search the same query on Bing, however, this is what you get:

You still get the same result as Google, but as you can see in the highlighted area, we also give you a set of related apps for you to consider. Seems quite trivial, right? It is not so trivial, though. Here is the roadmap to build and ship a feature like this:
The Hypothesis
The consideration for features like that start when we noticed a high number of queries from users looking for apps (iOS or Android). In addition, we know that related content, such as "Related Searches", gets a very healthy amount of engagement, and that app stores don't do a great job in terms of related content. We did some research across various features on Bing and also across the industry and realized that recommendation features and engines are crucial for a number of business - Netflix for instance is well-known to drive a lot of their business via their recommendation platform. So the hypothesis was that, given the high number of searches for apps, the high number of apps, and the fact that no one was providing a good recommendation engine (related apps) for this segment, we conjectured the viability of such a feature and decided to proceed with a prototype and finally with its implementation.

The Offline Process to Build the Clusters
The real magic starts here. We have in our index millions and millions of apps, but the question then became, given one app, how do we find related apps for it? An app has a number of metadata that we'll be using in this task, such as:

Ranking the Related Apps
Clusters are to some degree not ordered, so we need to come up with a ranking algorithm to decide which related apps to show first, and which ones to show last (order makes a huge difference in the user experience!). We make use again of our metadata and click info, and we don't need to resort to heavily on Machine Learning/Artificial Intelligence anymore: a simple mathematical function using key features like ratings, reviews and clicks allows us to come up with a simple but efficient ranking function. Done.

The Triggering Consideration
Many times in the search business we need to worry about when to trigger a certain feature. In this particular case here we did not have to worry about it: the apps were already triggering before, and we were just attaching the related apps to them. Technically speaking, here is how it works: we modify the MVVM Controller and View Model of the triggered app and if there is a set of related apps we then invoke a specific view to render those apps. No triggering consideration here then!

The Performance Versus Engagement Question
The next question that we had to answer was: how many related apps should we show? Show too few and users won't be happy and the engagement will certainly go down. Show too many and it will impact the overall Page Load Time which is equally undesirable. To answer this question we let the data do the hard work for us: we setup 4 experiments where we displayed 2, 4, 6 and 8 related apps. We then analyze the engagement numbers compared to the page load time and we're looking here for the point of diminishing returns. When we look at the data we noticed that the biggest jump in engagement happened when we showed no more than 4 related apps. From that point onward the page load time starts to grow quickly but the engagement ("healthy clicks") grows very slowly. Hence we were convinced, max of 4 related apps it was! (chart below is using anecdotal data not real one)

The User eXperience (UX)
We take a lot of care when building the final User Interface (UI) to present a certain feature to the users. We work with our awesome design team to come up with several different variations, and similar to the previous analysis, we do studies around user satisfaction based on engagement, we look at the PLT again, but we also look at many other metrics on our page. For example, one of the first UI variations that we had was showing larger icons and more app metadata, like the one below (which was not shipped!):

It did not perform as well as the one that we shipped: the extra size of the related apps was pushing too much data down, hurting PLT, and the extra metadata wasn't providing much value in terms of engagement numbers. After many rounds of A/B Tests, the data told us to go with the slimmer version, the one that you see in production today.
The Credits
100% to our Tech Download engineers Aman Singhal, Neelam Tiwari, Shantanu Sharma and John Yeung.

Must Write Some Code!
This is a coding blog so it is imperative to write some code before wrapping up. OK, let's calculate the Euclidean Distance of two points, but hey: use long to return the value to avoid overflow, and no need to calculate square root since it is expensive:
Long EuclideanDistance(Point P1, Point P2)
{
return ((long)P1.x-P2.x)*((long)P1.x-P2.x) + ((long)P1.y-P2.y)*((long)P1.y-P2.y);
}
Thanks for Reading It!!!
Hope you enjoyed!!! And here is me on the Big Island:

But behind those blue links and media content, there is some deep science, engineering and mathematics that take place.
In this post I'll explain the high-level process (well, there will be some details) to build a very small feature, but you'll see how much effort and science go into it.
Not rocket science, but gets very close to it.
At Bing (in particular the Visual System and SERP Experiences group) we've recently shipped a cool feature for mobile devices: say that you're searching on Google for a specific app: "1 second everyday app" (the current number #1 free app in the app store). This is what you get:

As you can see the very first result is what you're looking for. Job well done.
When you search the same query on Bing, however, this is what you get:

You still get the same result as Google, but as you can see in the highlighted area, we also give you a set of related apps for you to consider. Seems quite trivial, right? It is not so trivial, though. Here is the roadmap to build and ship a feature like this:
The Hypothesis
The consideration for features like that start when we noticed a high number of queries from users looking for apps (iOS or Android). In addition, we know that related content, such as "Related Searches", gets a very healthy amount of engagement, and that app stores don't do a great job in terms of related content. We did some research across various features on Bing and also across the industry and realized that recommendation features and engines are crucial for a number of business - Netflix for instance is well-known to drive a lot of their business via their recommendation platform. So the hypothesis was that, given the high number of searches for apps, the high number of apps, and the fact that no one was providing a good recommendation engine (related apps) for this segment, we conjectured the viability of such a feature and decided to proceed with a prototype and finally with its implementation.
The Offline Process to Build the Clusters
The real magic starts here. We have in our index millions and millions of apps, but the question then became, given one app, how do we find related apps for it? An app has a number of metadata that we'll be using in this task, such as:
- Title
- Description
- "Category" (as provided by the publisher, not super reliable though)
- Logo
- Seller
- Language
- Rating
- Developer web site
- Comments
- Etc.
What we want to do then is use this information to group together the apps that are very similar to each other (at least from the user's standpoint). We also have statistical information about clicks which we can use here too. In any case, what we wanted to do was to build clusters of similar apps. This is an Artificial Intelligence problem. There are many options here but we decided to go with Deep Structured Semantic Model or DSSM. DSSM can be used as (sort of, over-simplifying here) an extrapolation of K-Nearest Neighbor or KNN: applying a mathematical function to the metadata we can come up with points (DSSM actually projects vectors) on a plane (DSSM actually uses large N-dimensions), and using Euclidean Distance (DSSM actually uses a much more complicated algorithm for vector distances) the clusters can then be auto-formed in a non-supervised manner. After thoroughly testing the clusters, we then move on to the next step.

Clusters are to some degree not ordered, so we need to come up with a ranking algorithm to decide which related apps to show first, and which ones to show last (order makes a huge difference in the user experience!). We make use again of our metadata and click info, and we don't need to resort to heavily on Machine Learning/Artificial Intelligence anymore: a simple mathematical function using key features like ratings, reviews and clicks allows us to come up with a simple but efficient ranking function. Done.
The Triggering Consideration
Many times in the search business we need to worry about when to trigger a certain feature. In this particular case here we did not have to worry about it: the apps were already triggering before, and we were just attaching the related apps to them. Technically speaking, here is how it works: we modify the MVVM Controller and View Model of the triggered app and if there is a set of related apps we then invoke a specific view to render those apps. No triggering consideration here then!

The Performance Versus Engagement Question
The next question that we had to answer was: how many related apps should we show? Show too few and users won't be happy and the engagement will certainly go down. Show too many and it will impact the overall Page Load Time which is equally undesirable. To answer this question we let the data do the hard work for us: we setup 4 experiments where we displayed 2, 4, 6 and 8 related apps. We then analyze the engagement numbers compared to the page load time and we're looking here for the point of diminishing returns. When we look at the data we noticed that the biggest jump in engagement happened when we showed no more than 4 related apps. From that point onward the page load time starts to grow quickly but the engagement ("healthy clicks") grows very slowly. Hence we were convinced, max of 4 related apps it was! (chart below is using anecdotal data not real one)

The User eXperience (UX)
We take a lot of care when building the final User Interface (UI) to present a certain feature to the users. We work with our awesome design team to come up with several different variations, and similar to the previous analysis, we do studies around user satisfaction based on engagement, we look at the PLT again, but we also look at many other metrics on our page. For example, one of the first UI variations that we had was showing larger icons and more app metadata, like the one below (which was not shipped!):

It did not perform as well as the one that we shipped: the extra size of the related apps was pushing too much data down, hurting PLT, and the extra metadata wasn't providing much value in terms of engagement numbers. After many rounds of A/B Tests, the data told us to go with the slimmer version, the one that you see in production today.
The Credits
100% to our Tech Download engineers Aman Singhal, Neelam Tiwari, Shantanu Sharma and John Yeung.
Must Write Some Code!
This is a coding blog so it is imperative to write some code before wrapping up. OK, let's calculate the Euclidean Distance of two points, but hey: use long to return the value to avoid overflow, and no need to calculate square root since it is expensive:
Long EuclideanDistance(Point P1, Point P2)
{
return ((long)P1.x-P2.x)*((long)P1.x-P2.x) + ((long)P1.y-P2.y)*((long)P1.y-P2.y);
}
Thanks for Reading It!!!
Hope you enjoyed!!! And here is me on the Big Island:




Your post is really awesome. Your blog is really helpful.
ReplyDeleteFull Stack Online Training in Hyderabad
Great explanation to given on this post and i read our full content was really amazing,then the this more useful for me.
ReplyDeleteOracle Training in Chennai | Certification | Online Training Course | Oracle Training in Bangalore | Certification | Online Training Course | Oracle Training in Hyderabad | Certification | Online Training Course | Oracle Training in Online | Oracle Certification Online Training Course | Hadoop Training in Chennai | Certification | Big Data Online Training Course