LeetCode: Subsets II (binary manipulation for subsets of a set)
https://leetcode.com/problems/subsets-ii/, problem statement:
I've posted before a trick to generate subsets of a set non-recursively by using bit math, you can read the post here: https://anothercasualcoder.blogspot.com/2014/10/a-non-recursive-trick-for-subsets.html. Technique to solve this problem is exactly the same with two caveats:
Given a collection of integers that might contain duplicates, nums, return all possible subsets.
Note: The solution set must not contain duplicate subsets.
For example,
If nums =
If nums =
[1,2,2], a solution is:[ [2], [1], [1,2,2], [2,2], [1,2], [] ]
I've posted before a trick to generate subsets of a set non-recursively by using bit math, you can read the post here: https://anothercasualcoder.blogspot.com/2014/10/a-non-recursive-trick-for-subsets.html. Technique to solve this problem is exactly the same with two caveats:
- First sort the input array so that the key generation for the hash table becomes unique
- Then keep track of the solutions already seen using a hash table
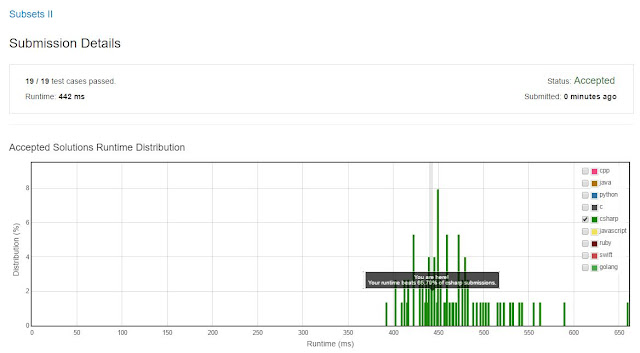
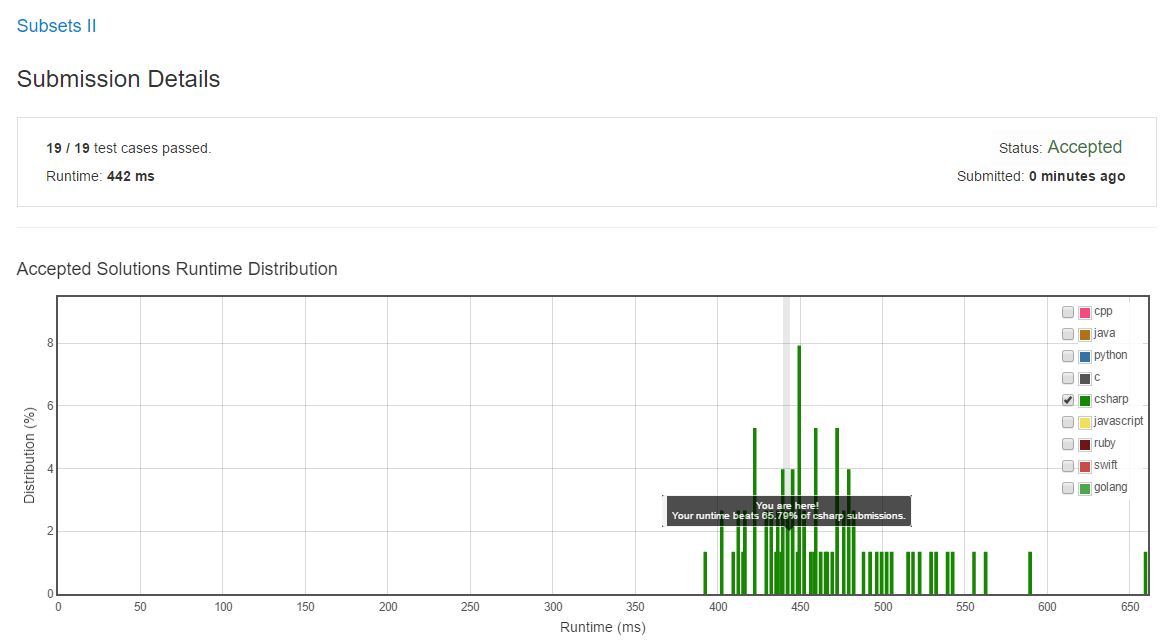
Complexity is still O(2^n) (actually nlog + 2^n). Beats more than half of the C# submissions. Code is down below, cheers, Marcelo.
Code:
public class Solution
{
public IList<IList<int>> SubsetsWithDup(int[] nums)
{
List<IList<int>> solution = new List<IList<int>>();
Array.Sort(nums);
Hashtable htSeen = new Hashtable();
for (int i = 0; i < Math.Pow(2, nums.Length); i++)
{
List<int> list = new List<int>();
int temp = i;
int index = nums.Length - 1;
string key = "";
while (temp > 0)
{
if (temp % 2 == 1)
{
list.Add(nums[index]);
key += nums[index] + "@";
}
index--;
temp /= 2;
}
if (!htSeen.ContainsKey(key))
{
solution.Add(list);
htSeen.Add(key, true);
}
}
return solution;
}
}



I love this problem! C++ 9ms solution below:
ReplyDeleteclass Solution {
public:
vector> subsetsWithDup(vector& nums) {
sort(nums.begin(), nums.end());
set> subsets;
for (int included = 0; included < (1 << nums.size()); ++included) {
vector subset;
for (int i = 0; i < nums.size(); ++i) {
if (included >> i & 1) subset.push_back(nums[i]);
}
subsets.emplace(subset);
}
vector> result(subsets.cbegin(), subsets.cend());
return result;
}
};
http://ideone.com/a5uTiH
Interestingly a recursive solution using vector to track included elements had the same performance, so compilers really rock these days :)
I'm not sure how much overhead using a string as a key adds, but having a custom hash code comparison using a list directly would probably help speeding things up for your implementation, even though I'm using a Red-Black tree as a set implementation and its logN performance is apparently good enough :) I'd probably still recommend using at least a HashSet instead of Hashtable because at the very least its Add method implementation returns a boolean indicating whether an element was actually added, so you could replace your check for duplicates with
if (htSeen.Add(key))
{
solution.Add(list);
}
so you'd have a single lookup overhead for new new lists instead of double (for ContainsKey + Add)
Keep them coming!